遂に理情名物であるところの「CPU 実験」が最終発表まで全て終わりました。この記事はその振り返り、という体のポエムになります。
CPU 実験とは?
CPU 実験の正式名称は「プロセッサ・コンパイラ実験」で1、その内容は「CPU、コンパイラ等を自作して、如何に速く与えられたプログラム(通称「レイトレ」)を動かせるか競う」というものです。
とはいえ 1 人でコンパイラから CPU まで作るのは労力が洒落にならないので、3~4 人ずつで班分けして以下の役割を分担します2。
- コア係
- CPU を実装する。
- FPU 係
- FPU(浮動小数点数の演算を行う回路)を実装する。
- コンパイラ係
- レイトレプログラムをコンパイルできるよう、mincamlという関数型言語のコンパイラを改造する。
- コンパイラに種々の最適化を組み込む。
- アセンブラ係
- コンパイラが出したアセンブリコードを、機械語に変換するプログラムを実装する。
- シミュレータ係
- 機械語を実行するインタプリタを実装する。
- 要望に応じてデバッグ機能を実装する。
上 2 つはハードウェア系、下 3 つはソフトウェア系です。そして今回僕が担当することになったのが、上で強調されている通り「コア係」でした。ということで、この記事では主にコア係の目線で話すことになります。
コア係とは?
コア係の説明で「CPU を実装する」と言いましたが、ブレッドボードなどで物理的に配線するわけではないですし、半田ごてを使ったりはしません3。
講義期間中、各班には「FPGA」という基盤が与えられます。 FPGA は簡単に言うと「ユーザがプログラムを介して配線を構成できる基盤」で、より抽象度の高いレベルでユーザが配線を構成することができます。
配線のプログラムには Verilog、SystemVerilog というハードウェア記述言語(HDL)を用います。プログラムのコンパイル、配線の最適化、基盤への書き込み等は vivado という統合開発環境(IDE)を使います。
というわけでコア係の仕事は、より正確には「CPU を HDL で実装する」ことになります。
資料がない?
ただし諸々の資料や講義がある他の科目と異なり、CPU 実験ではツールと FPGA 以外は何も与えられません。参考資料も土台となるプログラムも皆無です4。そんな中でどうやって CPU を作るのかと言うと、
- 過去の講義を復習する
- 歴代のブログを漁る
- 公式ドキュメントなどを読んで、種々の機能の使い方を学ぶ
- 本などを読んで CPU の基本的な構成を学ぶ
などをすることになります。このブログの末尾に僕が参考にした資料をまとめました。これから CPU 実験を体験する皆さんの力になれば幸いです。
ちなみにこの「何をすればいいか分からない」「公式ドキュメントを読まないといけない」といったところが「コア係はキツい」と言われる理由の 3 割くらいだと思っています。残り 7 割はハードウェア、vivado、verilog 特有の非自明なバグと、それらのデバッグの困難さです。
全体のスケジュール
僕がコア係としてどのようなスケジュールで開発をしたのかを簡単にまとめました。興味のない方は結果まで飛ばして大丈夫です。
10 月: 学習期
10 月中はパタヘネを通読してコアの構造を学んだり、ALU・レジスタ・デコーダ等の基本モジュールを実装しました。
これだけなら良さそうに聞こえますが、実は実機に一度も触れていません。 結果として諸々の知見を聞き逃してしまったので、これからコア係をやる人は積極的に地下5に通うことをオススメします。
11 月: 実装期
11 月から腹を括って実機に触ることにしました。いよいよ CPU 実験開始です。
第 1 週: L チカ
まず第 1 週に L チカをしました。先代の知見に圧倒的感謝(参考資料を参照)。ついでに実装済みの ALU とレジスタの動作確認もしました。
第 2 週: UART
第 2 週で UART を実装しました。UART 通信は AXI UART Lite という IP コアを使ったので、最初にそのドキュメントを読み込みました。
AXI の実装はハードウェア実験で実装したものをほとんど流用でき、バグを直して UART loopback が動きました。I/O 周りはバグを踏みやすい印象があったので怖かったですが、無事に乗り越えられて安心しました。
第 3 週前半: メモリ
第 3 週前半でメモリ周りを調べました。当初は AXI でメモリアクセスを行う予定でしたが、仕様が全然分からなかったので Block Memory Generator の native インターフェースを使うことにしました。
これは偶然にも良い選択でした。というのも、メモリアクセスは UART 通信と違ってかなり頻繁に行うため、AXI インターフェースでは遅すぎるのです。実際メモリアクセスは後に限界まで高速化することになります。
第 3 週後半: コア
第 3 週後半、いよいよコアのデバッグです。10 月中に実装したものを試しに動かして見るも、流石にそう簡単には動きません。
そこで最初は「1 から 100 を出力する」という簡単なプログラムから始めました。シミュレータ(vivado)とシミュレータ(ソフトウェア)を睨みながら、非想定の挙動を見つけて修正…を繰り返し、なんとか動かすことができました。それからさらにデバッグを重ね、遂に「再帰フィボナッチ」を動かすことができました。これでコアは概ね完成です。
ここまで早くデバッグが終わったのは、一重に優秀なシミュレータ(ソフトウェア)のおかげです。ちなみにどうやってデバッグするかというと、プログラムカウンタ・レジスタの中身がシミュレータ同士と一致しなくなった場所を二分探索です。地道な作業ですが、これが一番効果的だったりします。
第 4 週〜: 完動
その後 FPU の方も完成し、僅かな修正によってレイトレを動かすことに成功しました。最後に謎の黒い線が出てしまい、どこの演算の精度不足が原因かを探るので四苦八苦した記憶があります。
12 月~1 月: 倦怠期
それからしばらくは CPU 実験に触れませんでした。その理由を上げるとすれば、
- 11 月の疲れが押し寄せてきた
- パイプラインの構想が詰めきれなかった
- 期末試験があった
等があります。特に期末試験の影響は大きく、次に CPU 実験に触れたのは全ての試験が終わった 1 月後半からでした。
2 月: ラストスパート
いよいよ最終月ということで、本格的に高速化に取り組み始めます。
2nd 対応
最初にやったのが 2nd アーキテクチャへの対応です。
班にもよりますが、うちの班は
- 完動を第一とした 1st アーキテクチャ
- 1st の反省を踏まえ、高速化を視野にいれた 2nd アーキテクチャ
の 2 段階にアーキテクチャが分かれていました。 といっても CPU の構造が根幹から変わるような命令は追加されなかったため、コア係としてはデコーダを作り直すだけでほとんどは事足りました。
ちなみにこの裏でコンパイラ係は mincaml を Scala でフルスクラッチしていました。それでいて最終的な命令数は全体で恐らく最少なので、正に狂気です。
パイプライン化
次にいよいよパイプライン化を実装することにしました。
「パイプライン化はバグったら終わる」とずっと思っていたので、設計を極力詰めてから実装を始めるようにしました。 上の倦怠期の間も何もしていなかったわけではなく、パタヘネを読み直したり、回路図を描いて設計を整理したりしました。以下はその回路図です。
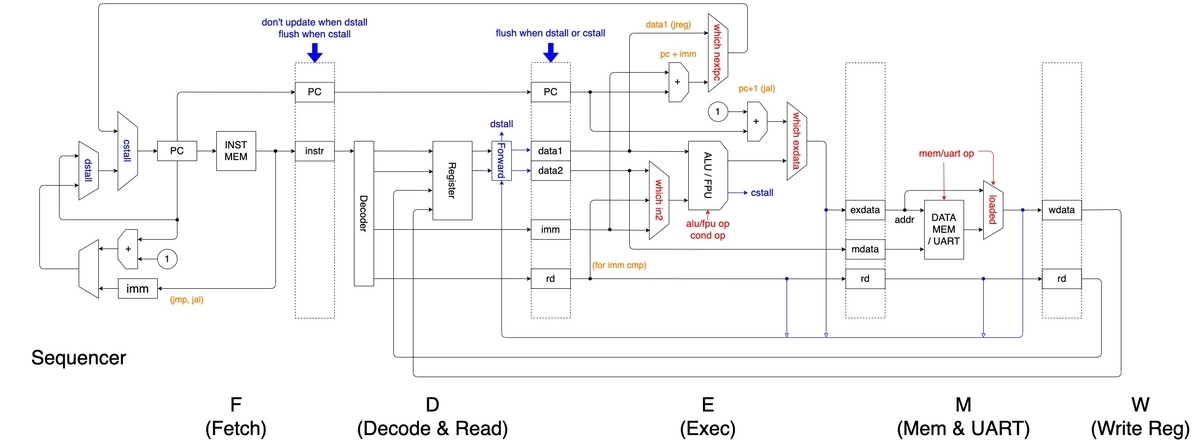
しかしやはりバグというのは存在するもので、またしてもシミュレータとにらめっこをすることになりました。特にパイプライン化は「今どの命令を実行しているのか」が分かりにくいため、慣れるまでデバッグにかなり手こずりました。
それでも徹夜でバグを潰し、結果として実行時間は半分以下になりました。この時点で動作周波数は 20MHz、コンテストは 200 秒程度でした。
クロック分割
最後の大きな改善として、動作周波数を上げました。 この作業でメインとなるのは FPU 係で、FPU のクリティカルパスをクロック分割することで減らしてもらうことになります。
FPU 係の努力の結果として、動作周波数は 20MHz から 180MHz まで上がりました。なぜか vivado 上では最大周波数が 130MHz だったのですが、最長のワイヤ線が本来あるはずのないものだったので試しに上げてみたら 180MHz まで動きました。130MHz 辺りでなぜか周波数が上がらなくなったら試してみるといいと思います。
最終結果、所感
最終的なスペックは以下のようになりました。
- 命令数: 10.84 億
- 動作周波数: 130MHz
- コンテストの動作時間: 27.375sec
目標としていた 30 秒を割ることができました。しかし命令数的にコアがもっと頑張れば 20 秒を割れてもおかしくないと思っていて、コア係としての力不足を感じました。
コア係をやって良かったか
最初の講義でコア係に立候補したのは完全に気まぐれでしたが、結果としてコア係になったのは正解だったと思います。その理由をいくつか挙げると、
- CPU の構成に対する学びがかなり大きかった
- 普段から地下6によく来るタイプなので向いていた
- 完動だけならそこまで大変な方ではない
などがあります。3 つ目については、傍らから見た感じコンパイラ係の方が遥かに大変なように思いました。「労力」に対する「学べること」のコスパを考えると、コア係が一番かな、という印象です。
参考資料
L チカまでの過程がかなり丁寧に書かれた神資料です。最初はこれを読んで vivado の使い方を学ぶと良いです。
前セメスターで開講された「計算機構成論」の教科書です。日本語が怪しい箇所がままありますが、コアを実装する上で十分な内容が簡潔にまとまっています。
俗に「パタヘネ」と呼ばれる本です。厚さから威圧感を受けますが、平易な文章と豊富な図で、かなり詳しくコアの実装方針について書かれている良書です。 特にパイプラインの項は非常に参考になるので、実装前に一読することを強く推奨します。 ちなみに下巻は余興とかやらない限りは読まなくて大丈夫です。
講義で使われる FPGA である、KCU105 の公式ドキュメントです。制約ファイルを書くときに、ピンの名前を調べるために使いました。並列化とか余興をやろうとすると、さらに読む必要があるかもしれません。
UART 通信を行う手段として AXI UART Lite という IP コアを使う方法があるのですが、その公式ドキュメントです。 これは Chapter2 までちゃんと読んだほうが良いです。非自明な仕様がそれなりにあります。
BRAM を使う上で用いた、Block Memory Generator という IP コアの公式ドキュメントです。しかし上の方にはプロトコルが存在せず、下の方の資料にありました。
-
厳密には、「プロセッサ実験」と「コンパイラ実験」という 2 つの講義が 1 つの科目として扱われている感じです。CPU 実験に当たるのが「プロセッサ実験」で、「コンパイラ実験」では係に関わらず全員がコンパイラに触れることになります。 ↩︎
-
4 人に対して係が 5 つありますが、大抵の班はアセンブラ係とシミュレータ係を 1 人が担うことになります。3 人班はかなり大変です。 ↩︎
-
学科ガイダンスの資料を見るに、昔は物理レベルの配線をやっていたようです。恐ろしい…。 ↩︎
-
「資料が何もない」というのは若干の誇張で、1 つ前のセメスターで開講される「ハードウェア実験」「計算機構成論」の資料が参考になります。それでも CPU 実験独自の資料がないのは事実で、多分「これまでの講義の知識を使ってね」というノリだと個人的に考えています。 ↩︎
-
理学部情報科学科の学生控室のこと。回路の合成・FPGA の書き込み等はここでないと行えない。 ↩︎
-
上の注釈を参照。 ↩︎